LM Studio 简介
LM Studio 是一款基于 Electron 开发的本地大模型运行平台,支持 GGUF/GPTQ 等主流量化格式,并具有零配置启动(自动识别模型架构)、跨平台支持(Windows/macOS/Linux)、可视化 GPU 资源监控、内置 OpenAI 兼容的 API 端点等功能。LM Studio 是 DeepSeek 官方推荐的模型部署方式,此外,它还支持部署 Qwen3 等开源模型。
技术架构:
1
2
3
4
5
6
7
8
9
|
+------------------+ +------------------+ +------------------+
| Model File |------>| Quant Decoder |------>| Inference Engine |
+------------------+ +------------------+ +---------+--------+
|
+---------------+---------------+
| |
+-------v-------+ +-------v-------+
| CPU (AVX2) | | GPU (CUDA) |
+---------------+ +---------------+
|
实验环境准备
- 操作系统:Linux x64
- 内存/显存:建议 16GB 及以上
- 存储空间:建议空余至少 40GB 可用空间
由于仅探究部署方法,因此对于模型都使用 1.5b 参数,这对于设备配置的要求一般,中高端配置的设备都可以部署。
这里先在支持 CUDA 的设备上测试部署。
步骤一:安装 LM Studio
- 访问LM Studio 官网下载 Windows/Linux 安装包
- 按向导完成安装
linux 版本为 appimage 格式,直接 chmod +x 赋予执行权限,然后运行即可。
- 启动后会让用户安装模型,先跳过
步骤二:获取 DeepSeek/Qwen 模型
- 在 LM Studio 中选择右侧的 discover 按钮,打开模型搜索下载页面
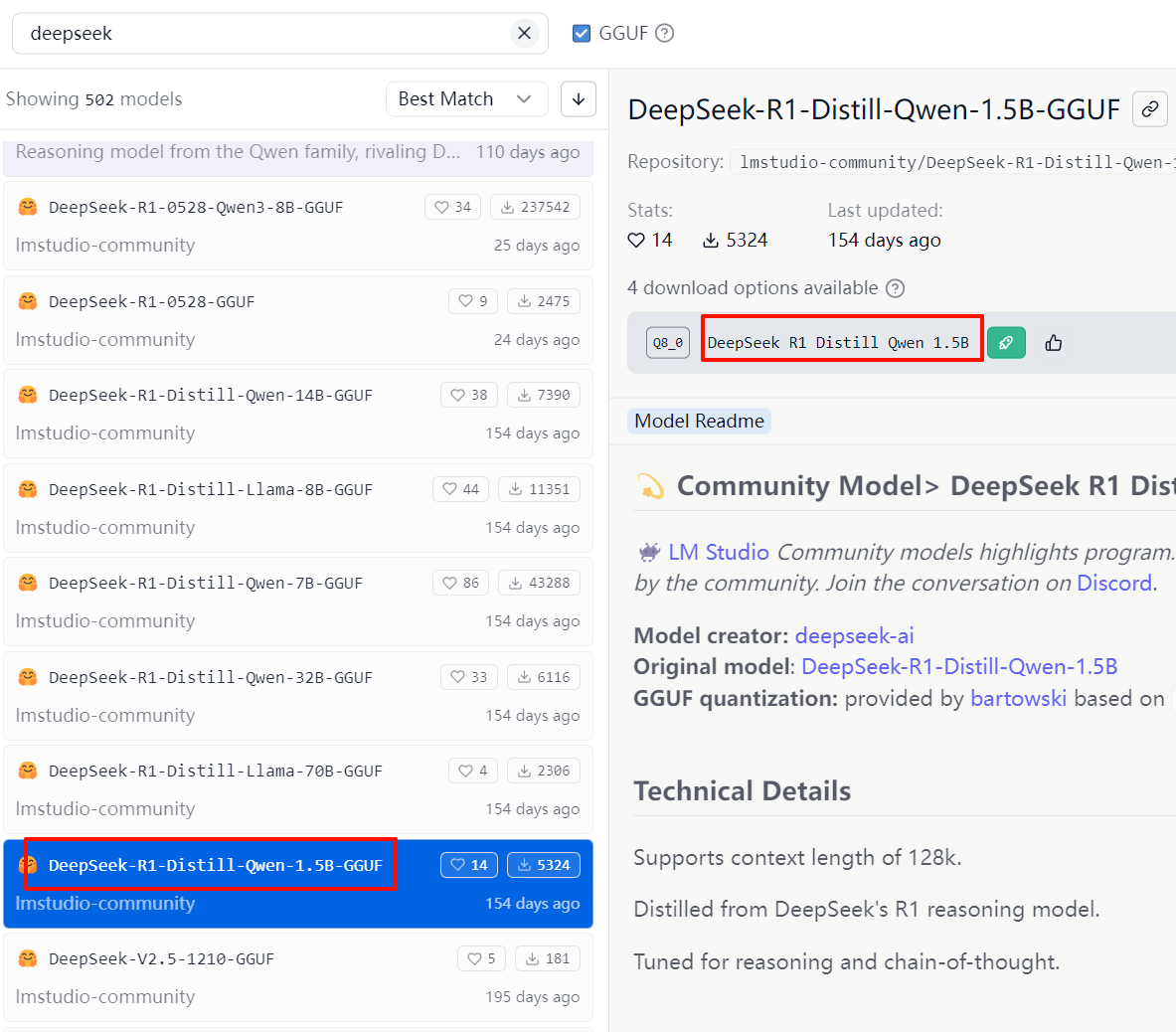
- 搜索 deepseek,在列表中选择 1.5b 的模型用于部署,模型大小约 1GB。
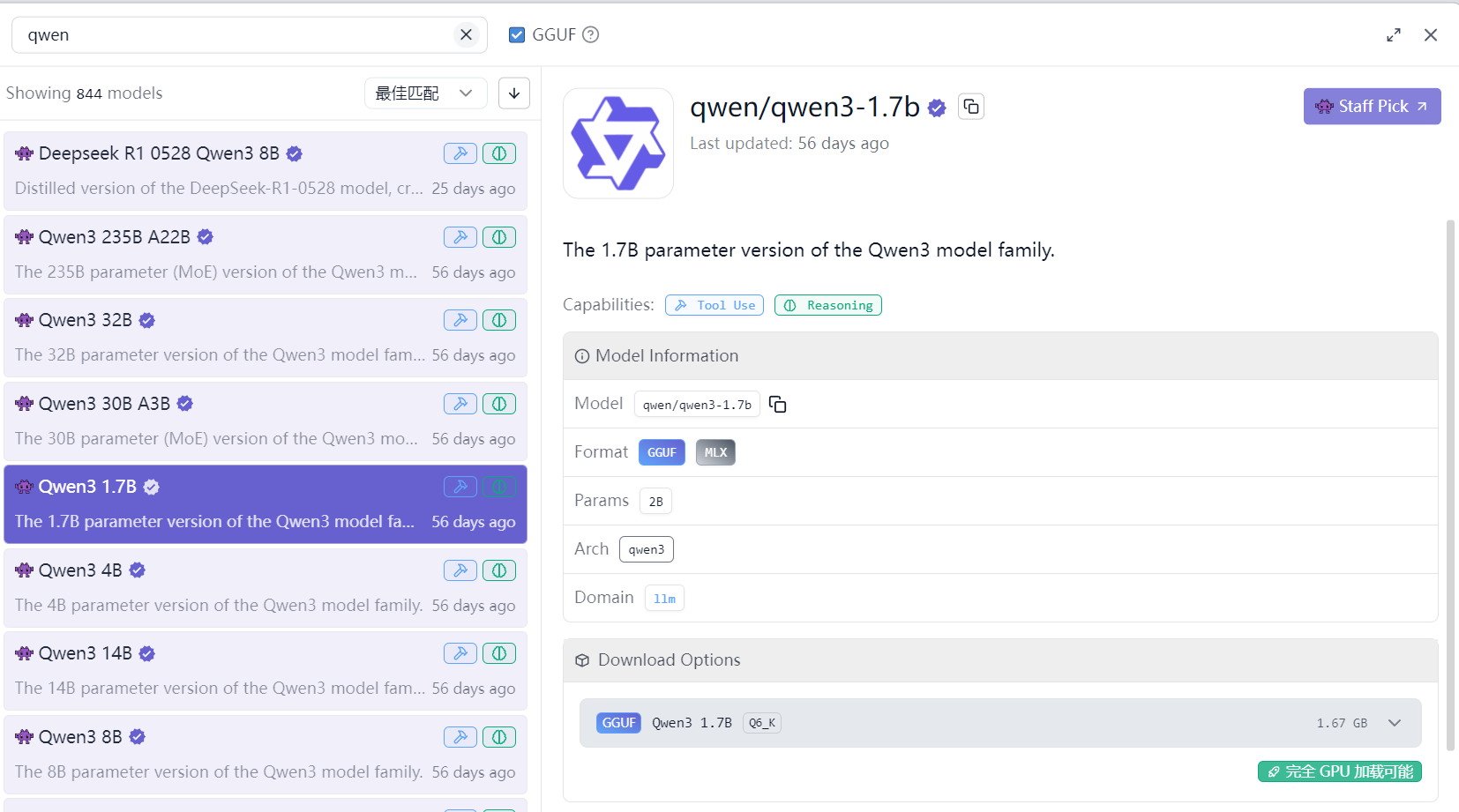
- 搜索 qwen,在列表中选择 1.7b 模型用于部署,模型大小约 2GB。
- 点击 Download 进行下载
步骤三:模型加载
- 打开 LM Studio,点击左侧"My Models"面板
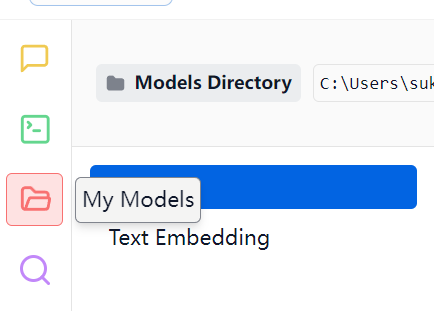
- 左上角可以修改模型的存储位置,指定存放 DeepSeek/Qwen3 模型文件的目录

- 等待模型下载索引完成后即可在列表看到模型
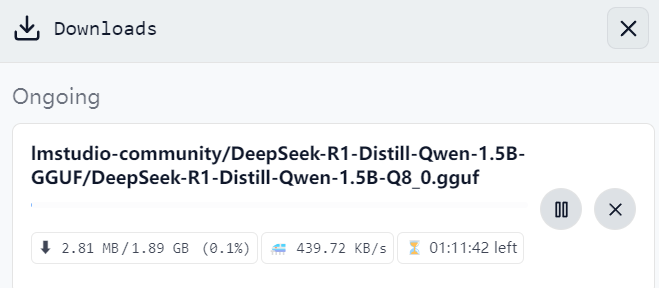
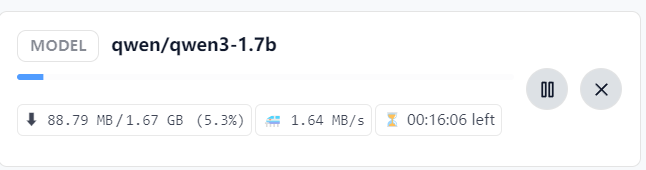
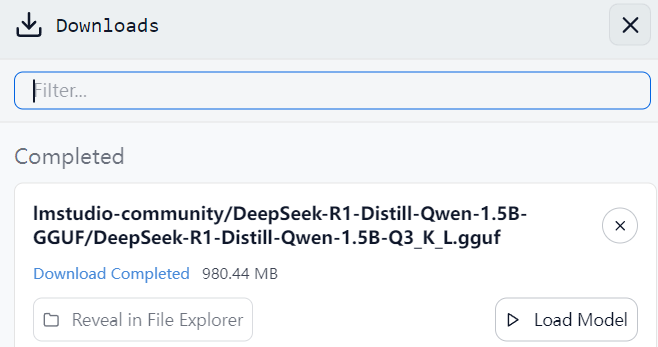 由于存在网络问题,可能需要通过代理才能满速下载,解决网络问题后下载设备可以运行的 “DeepSeek-R1-Distill-Qwen-1.5B-GGUF” 模型。
由于存在网络问题,可能需要通过代理才能满速下载,解决网络问题后下载设备可以运行的 “DeepSeek-R1-Distill-Qwen-1.5B-GGUF” 模型。
步骤四:运行推理
以 DeepSeek 模型为例,Qwen3 模型类似:
- 点击顶部"Chat"标签页
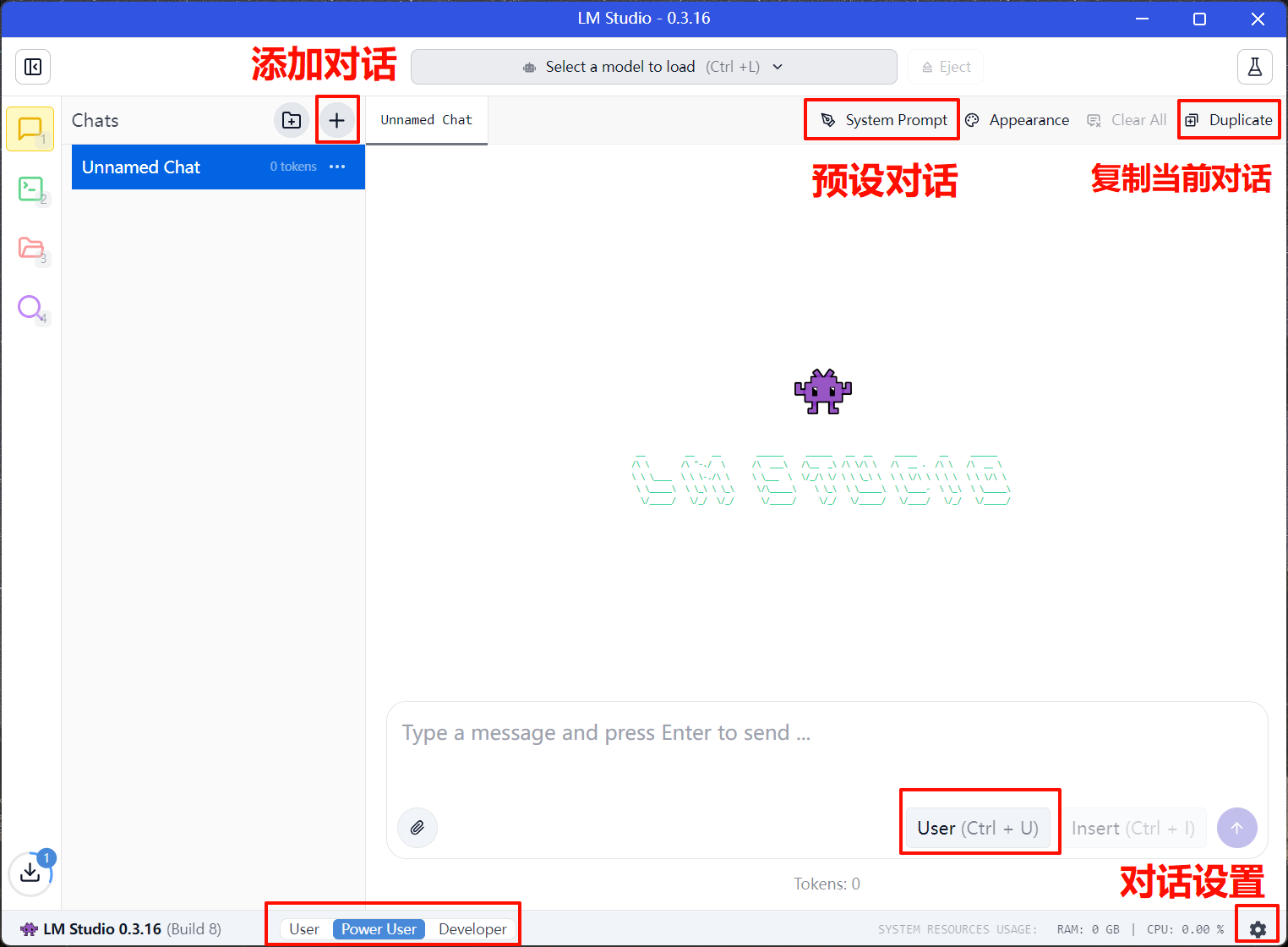
可以进行一些对话配置,也可以保持默认。
- 从右侧面板选择已加载的 DeepSeek/Qwen3 模型。

- 在下方输入框输入 prompt,从选择的模型获取 response。
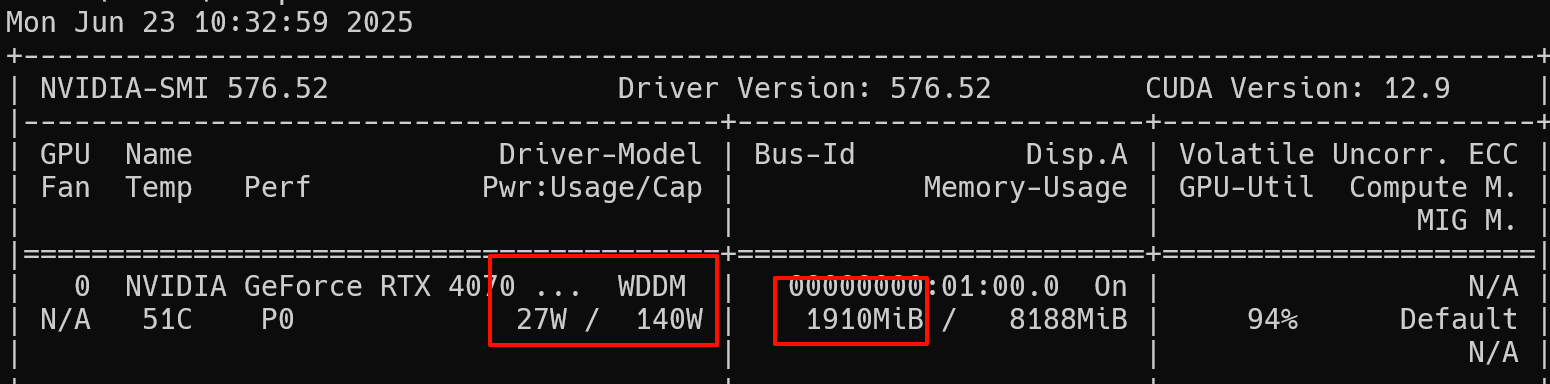
通过 nvidia 信息面板(功耗、显存、正在运行的程序等)可以看到 LM Studio 会自动调用 GPU 进行推理。
API 调用
并非所有场景都具备图形界面功能,因此通过编程语言、命令行进行模型调用也是必须的。
LM Sudio API 文档
可以通过以下四种方式调用 LM Studio 的接口:
- TypeScript SDK - lmstudio-js
- Python SDK - lmstudio-python
- LM Studio REST API(新功能,测试版)
- OpenAI 兼容性端点
处于兼容性考虑,我们使用 OpenAI 兼容端口进行测试。
首先在 Python 中安装 OpenAI 包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
lmstudio> uv pip install openai
Using Python 3.13.5 environment at
Resolved 17 packages in 3.13s
Prepared 15 packages in 2.67s
░░░░░░░░░░░░░░░░░░░░ [0/15] Installing wheels... warning: Failed to hardlink files; falling back to full copy. This may lead to degraded performance.
If the cache and target directories are on different filesystems, hardlinking may not be supported.
If this is intentional, set `export UV_LINK_MODE=copy` or use `--link-mode=copy` to suppress this warning.
Installed 15 packages in 267ms
+ annotated-types==0.7.0
+ anyio==4.9.0
+ certifi==2025.6.15
+ distro==1.9.0
+ h11==0.16.0
+ httpcore==1.0.9
+ httpx==0.28.1
+ idna==3.10
+ jiter==0.10.0
+ openai==1.90.0
+ pydantic==2.11.7
+ pydantic-core==2.33.2
+ sniffio==1.3.1
+ typing-extensions==4.14.0
+ typing-inspection==0.4.1
|
进入“开发者”
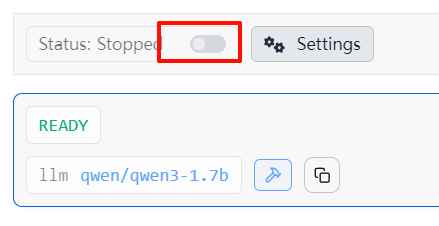
确保模型已被正确加载,然后点击 settings 旁边的按钮,开启服务。
示例 Python 代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# Example: reuse your existing OpenAI setup
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
completion = client.chat.completions.create(
# model="qwen/qwen3-1.7b",
model="deepseek-r1-distill-qwen-1.5b",
messages=[
{"role": "system", "content": "Always answer in rhymes."},
{"role": "user", "content": "Introduce yourself."}
],
temperature=0.7,
)
print(completion.choices[0].message)
|
需要 Qwen 模型的话,将 model=后面的内容改为"qwen/qwen3-1.7b"即可,前提是该模型已经加载。
运行代码,得到以下回复:
1
2
|
lmstudio> uv run ./main.py
ChatCompletionMessage(content='<think>\nOkay, so I need to help someone who wants a always-rhyming answer that introduces themselves. They also want it in a funny way, maybe using some puns or wordplay......"', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None)
|
表明已经正确调用 API
LM Studio 下方也能看到相关的日志。
常见性能优化方式:
- 使用量化程度更高的模型版本(如 q5_k_m)。
- 如果使用 CPU 推理,可以添加虚拟内存以运行更大的模型。
- 在 NVIDIA 显卡设备上启用 CUDA 加速,或在有 NPU 的设备上启用推理加速。
- 使用 RAM Disk 而非硬盘存放模型文件以提升加载速度。
目前遇到的问题
- LM Studio 在 linux 平台上对 ARM 不支持,需要另想办法。
- 如何在昇腾上启用硬件加速,需要进一步试验。